GAN,全称 Generative Adversarial Nets,中文名是生成对抗式网络。对于 GAN 来说,最通俗的解释就是“造假者-鉴别者”的解释,如艺术画的伪造者和鉴别者。一开始伪造者和鉴别者的水平都不高,但是鉴别者还是比较容易鉴别出伪造者伪造出来的艺术画。但随着伪造者对伪造技术的学习后,其伪造的艺术画会让鉴别者识别错误;或者随着鉴别者对鉴别技术的学习后,能够很简单的鉴别出伪造者伪造的艺术画。这是一个双方不断学习技术,以达到最高的伪造和鉴别水平的过程。 然而,稍微深入了解的读者就会发现,跟现实中的造假者不同,造假者会与时俱进地使用新材料新技术来造假,而 GAN 最神奇而又让人困惑的地方是它能够将随机噪声映射为我们所希望的正样本,有噪声就有正样本,这不是无本生意吗,多划算。
另一个情况是,自从 WGAN 提出以来,基本上 GAN 的主流研究都已经变成了 WGAN 上去了,但 WGAN 的形式事实上已经跟“伪造者-鉴别者”差得比较远了。而且 WGAN 虽然最后的形式并不复杂,但是推导过程却用到了诸多复杂的数学,使得我无心研读原始论文。这我要找从一条简明直观的线索来理解 GAN。幸好,经过一段时间的思考,有点收获。
在正文之前,先声明:笔者所有的 GAN 的知识,仅仅从网上的科普文所读而来,我并没有直接读过任何关于 GAN 的论文,因此,文中的结果可能跟主流的结果有雷同,也可能有很大出入,而且本文的讲述方法并不符合 GAN 的历史发展进程。严谨治学者慎入。
注:如无指明,本文所谈到的 GAN 都是广义的,即包括原始 GAN、WGAN 等等,对它们不作区分。文中出现的正样本、真实样本,都是指预先指定的一批样本,而生成样本则指的是随机噪声通过生成模型 G 变换所得的结果。
一道经典的面试题是:如果有一个伪随机数程序能够生成 [0,1] 之间的均匀随机数,那么如何由它来生成服从正态分布的伪随机数?比如怎么将 U[0,1] 映射成 N(0,1)?
这道题不同的角度有不同的做法,工程上的做法有:同时运行 n 个这样的伪随机数程序,每步产生 n 个随机数,那么这 n 个数的和就近似服从正态分布了。不过,这里不关心工程做法,而关心理论上的做法。理论上的做法是:将 X∼U[0,1] 经过函数 Y=f(X) 映射之后,就有 Y∼N(0,1) 了。设 ρ(x) 是 U[0,1] 是概率密度函数,那么 [x,x+dx] 和 [y,y+dy] 这两个区间的概率应该相等,而根据概率密度定义,ρ(x) 不是概率,ρ(x)dx 才是概率,因此有
注意到累积分布函数是无法用初等函数显式表示出来的,更不用说它的逆函数了。说白了,Y=f(X) 的 f 的确是存在的,但很复杂。正态分布是常见的、相对简单的分布,但这个映射已经这么复杂了。如果换了任意分布,甚至概率密度函数都不能显式写出来,那么复杂度可想而知。
现在我们将问题一般化:如何找到映射 Y=f(X),把服从均匀分布 X 映射到指定的分布?在一般情形下,这个指定的分布是通过给出一批具体的分布样本 Z=(z1,z2,…,zN) 来描述的(比如,给出一批服从正态分布的随机数,而不是给出概率密度
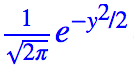
这个问题相当一般化,跟 GAN 所做的事情也是一样的。也就是说,GAN 也是希望把均匀的随机噪声映射成特定分布,这个特定分布由一组“正样本”描述。这样的理解就可以回答我们开头的一个小问题了:为什么 GAN 可以将噪声变换成正样本?事实上 GAN 并不是学习噪声到正样本的变换,而是学习均匀分布到指定分布的变换。假如学习成功了,那么输入一个随机噪声,那么就变换成指定分布的数据,而通常来说我们指定的分布是一个比较“窄”的分布(比如指定的正样本是某一类图片的集合,但事实上图片无穷无尽,某一类的图片是相当窄的),所以都会映射到我们眼中的“正样本”去。
前面正态分布的例子已经表明,这个映射 f 通常都是很复杂的,因此没必要求它的解析解。这时候“神经”就登场了:熟悉神经网络的读者都知道,我们总可以用一个神经网络来拟合任意函数,因此,不妨用一个带有多个参数的神经网络 G(X,θ) 去拟合它?只要把参数 θ 训练好,就可以认为 Y=G(X,θ) 了。
可是,问题又来了:拟合什么目标呢?我们怎么知道 Y=G(X,θ) 跟指定的分布是很接近的呢?
让我们把问题再理清楚一下:我们现在有一批服从某个指定分布的数据 Z=(z1,z2,…,zN),我们希望找到一个神经网络 Y=G(X,θ),将均匀随机数 X 映射到这个指定分布中来。
需要特别指出,我们是要比较两个分布的接近程度,而不是比较样本之间的差距。通常来说,我们会用 KL 距离来描述两个分布的差异:设 p1(x),p2(x) 是两个分布的概率密度(当然,还有其他距离可以选择,比如 Wasserstein 距离,但这不改变下面要讨论的内容的实质),那么:

如果是离散概率,则将积分换成求和即可。KL 距离并非真正的度量距离,但是它能够描述两个分布之间的差异,当它是 0 时,表明两个分布一致。但因为它不是对称的。有时候将它对称化,得到 JS 距离:
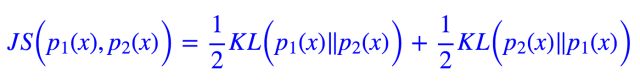
咦?怎么又回到概率密度了?不是说没给出概率密度吗?没办法,公式就是这样,只好估算一下咯。假设我们可以将实数域分若干个不相交的区间 I1,I2,…,IK,那么就可以估算一下给定分布 Z 的概率分布。

其中 #(zj∈Ii) 表示如果 zj∈Ii,那么取值为 1,否则为 0,也就是说大家不要被公式唬住了,上式就是一个简单的计数函数,用频率估计概率罢了。
接着我们生成 M 个均匀随机数 x1,x2,…,xM(这里不一定要 M=N,还是那句话,我们比较的是分布,不是样本本身,因此多一个少一个样本,对分布的估算也差不了多少。),根据 Y=G(X,θ) 计算对应的 y1,y2,…,yM,然后根据公式可以计算:
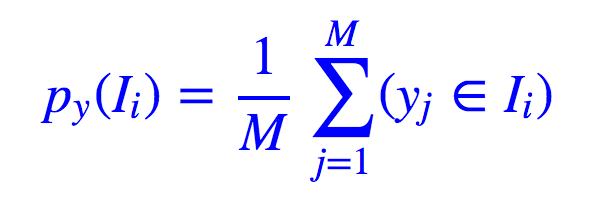
现在有了 pz(Ii) 和 py(Ii),那么我们就可以算它们的差距了,比如可以选择 JS 距离:
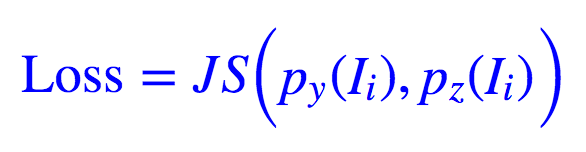
注意 yi 是由 G(X,θ) 生成的,所以 py(Ii) 是带有参数 θ 的,因此可以通过最小化 Loss 来得到参数 θ 的最优值,从而决定网络 Y=G(X,θ)。
假如我们只研究单变量概率分布之间的变换,那上述过程完全够了。然而,很多真正有意义的事情都是多元的,比如在 MNIST 上做实验,想要将随机噪声变换成手写数字图像。要注意 MNIST 的图像是 28*28=784 像素的,假如每个像素都是随机的,那么这就是一个 784 元的概率分布。按照我们前面分区间来计算 KL 距离或者 JS 距离,哪怕每个像素只分两个区间,那么就有 2784≈10236 个区间,这是何其巨大的计算量!
终于,有人怒了:“干嘛要用你那逗比的 JS 距离,自己用神经网络造一个距离!”于是他写出带参数 Θ 的神经网络:
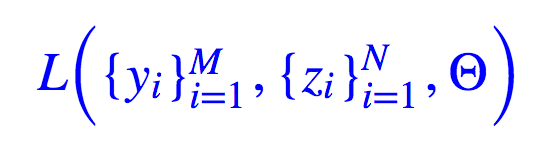
也就是说,直接将造出来的 yi 和真实的 zi 都放进去这个神经网络一算,自动出来距离,多方便。这个思想是里程碑式的,它连距离的定义都直接用神经网络学了,还有什么不可能学的呢?

接着,别忘记我们是描述分布之间的距离而不是样本的距离,而分布本身跟各个 yi 出现的顺序是没有关系的,因此分布之间的距离跟各个 yi 出现的顺序是无关的,也就是说,尽管 L 是各个 yi 的函数,但它必须全对称的!这是个很强的约束,当然,尽管如此,我们的选择也有很多,比如:

也就是说,我们先找一个有序的函数 D,然后对所有可能的序求平均,那么就得到无序的函数了。当然,这样的计算量是 ��(M!),显然也不靠谱,那么我们就选择最简单的一种:

“等等,你的标题是 GAN,你讲了那么一大通,我怎么没感觉到半点 GAN 的味道呀?对抗在哪里?” 这位看官您别急,马上就有了。

问题是:D(Y,Θ) 怎么训练?别忘了,之前的 G(X,θ) 还没有训练好,现在又弄个 D(Y,Θ) 出来,越搞越复杂,小心跳到坑里出不来了。
因为 D(Y,Θ) 的均值,也就是 L,是度量两个分布的差异程度,这就意味着,L 要能够将两个分布区分开来,即 L 越大越好;但是我们最终的目的,是希望通过均匀分布而生成我们指定的分布,所以 G(X,θ) 则希望两个分布越来越接近,即 L 越小越好。这时候,一个天才的想法出现了:互怼!不要怂,gan!
首先我们随机初始化 G(X,θ),固定它,然后生成一批 Y,这时候我们要训练 D(Y,Θ),既然 L 代表的是“与指定样本 Z 的差异”,那么,如果将指定样本 Z 代入 L,结果应该是越小越好,而将 Y 代入 L,结果应该是越大越好,所以:
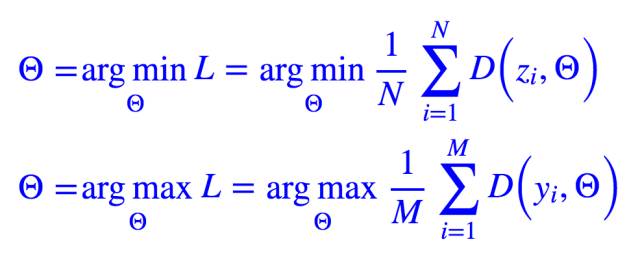
然而有两个目标并不容易平衡,所以干脆都取同样的样本数 B(一个 batch),然后一起训练就好:
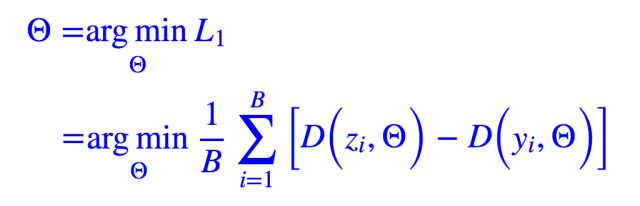
很自然,G(X,θ) 希望它生成的样本越接近真实样本越好,因此这时候把 Θ 固定,只训练 θ 让 L 越来越小:

1. 这里的 Loss 写法跟传统的 GAN 相反,习惯性的做法是让真实样本的LL越大越好,但这只不过跟本文差了个负号而已,不是本质的问题;
2. 从 GAN 开始,D 这个神经网络就被赋予了“判别器”的意义,但在这里 D 本身是没有意义的(正如我们不能说某个数是不是正态分布的),只有 D 的平均值 L 才代表着与真实分布的差距(我们只能根据一批数据来估计它是否服从正态分布),所以从这里也可以看到,GAN 不能单个样本地训练,至少成批训练,因为有一批样本才能看出统计特征;
3. 咋看上去 D 只是个二分类问题,而 G 则要把噪声映射为正样本,貌似 D 应该比 G 要简单得多?事实并非如此,它们两者的复杂度至少是相当的。我们可以直观考虑一下它们的工作原理:因为 D 的均值 L 直接就给出了输入的数据与指定分布的差异,而要真的做到这一点,那么 D 要把所有的“正样本”(在某种程度上)都“记住”了才行;而 G 要生成良好的正样本,基本上也是“记住”了所有的正样本,并通过随机数来插值输出。因此两个网络的复杂度应该是相当的(当然这里的“记住”是形象理解,不是真的记住了,不然就是过拟合了);
4. 既然 L1 是样本的分布差,那么 L1 越大,意味着“伪造”的样本质量越好,所以 L1 同时也着 GAN 训练的进程,L1 越大,训练得越好。(D 希望 L1 越小越好,G 希望 L1 越大越好,当然是 G 希望的结果,才是我们希望的。其实也可以这样理解,G 的损失 L2,其实就相当于 −L1,但是因为 D 的权重已经固定了,所以有关真实样本那一项是个,因此只剩下伪造样本那一项,即 L2,但 L2 是个绝对值,我们关心的是相对值,所以 −L1 是我们关心的,它越小越好,相当于 L1 越大越好。)
稍微思考一下,我们就发现,问题还没完。我们目前还没有对 D 做约束,不难发现,无约束的话 Loss 基本上会直接跑到负无穷去了。
因此,有必要给 D 加点条件,一个比较容易想到的方案是约束 D 的范围,比如能不能给 D 最后的输出加个 Sigmoid 激活函数,让它取值在 0 到 1 之间?事实上这个方案在理论上是没有问题的,然而这会造成训练的困难。因为 Sigmoid 函数具有饱和区,一旦 D 进入了饱和区,就很难传回梯度来更新 G 了。
最好加什么约束呢?我们应该尽可能从基本原理出发来找寻约束,尽量避免加入人工因素。我们回到距离的作用上来看:距离是为了表明两个对象的差距,而如果对象产生的微小的变化,那么距离的波动也不能太大,这应该是对距离基本的稳定性要求,“失之毫厘,谬以千里”是会产生浑沌的,数学模型不应该是这样。从这个角度来看,那个所谓的“JS 距离”,根据就不是距离了,因为就算对于伯努利分布 {0:0.1,1:0.9} 和 {0:0,1:1},这两个相似的分布算出来的“距离”居然是无穷大(因为出现了 0.1/0 这一项)。
放到我们的 D 中,这个约束我们该怎么体现呢?假如某个样本不是 yi 而是 y′i,假设 ‖yi−y′i‖(用两竖表示欧式距离,因为 y 可能是个多元向量)并不是十分大,那么会对分布造成一定的影响。这个影响有多大呢?显然不会大,因为分布是一批样本的统计特征,如果只是稍微改变了一个样本,那么分布的变化显然不能大的。而我们知道,分布的距离用 D 的均值 L 来描述,只改变一个 yi,所造成的分布差正比于:

我们希望 yi′→yi 时,自然地就有,怎么实现这一点呢?一个简单的方案是 D 满足以下约束:
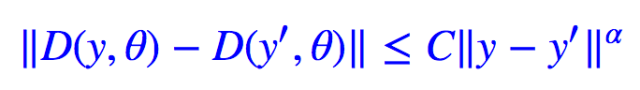
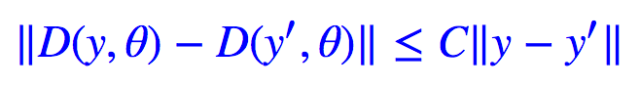
这就是数学中常见的Lipschitz 约束。如果能够满足这个约束,那么距离就能满足稳定性要求。注意这是个充分条件,不是必要条件,也可以使用其他方案。但不得不说,这是个简单明了的方案。而使得函数 D 满足 Lipschitz 约束的一个充分条件就是:
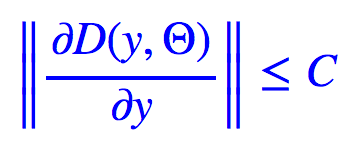
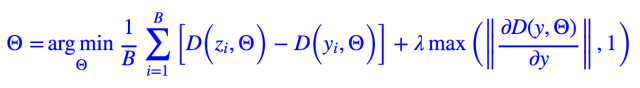
当然惩罚是“软约束”,最终的结果不一定满足这个约束,但却会在约束上下波动。也就是说虽然我们指定了 C=1,但最终的 C 却不一定等于 1,不过会在 1 上下波动,而这也不过是一个更宽松的 Lipschitz 约束而已,我们不在乎 C 的具体大小,只要 C 有就好。另外,约束的加法不是唯一的,WGAN 的作者 Martin Arjovsky 在他的论文中提出的加法为:
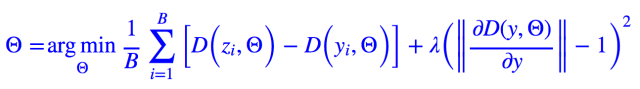
不过,的惩罚项都是形式而已,我们还没给出具体的计算方法。理论上最好能够对所有的 y(全空间)都算一遍
然后取平均,显然这是做不到的。那么只好用一个退而求其次的方案:只对真实样本 zi 和生成样本 yi 算。但这样约束范围貌似也太小了,所以干脆在真实样本和生成样本之间随机插值,希望这个约束可以“布满”真实样本和生成样本之间的空间,即:
最后,有人会反驳,梯度有,只不过是 Lipschitz 约束的充分条件,为啥不直接将 Lipschitz 约束以差分形式加入到惩罚中去呢?(其实有这个疑问的最主要的原因,是很多深度学习框架并没有提供梯度函数;另外,尽管 tensorflow 提供了梯度函数,但如果判别器用的是 RNN,那么梯度函数也是不可用的。)事实上,这样做某种意义上更加合理,我觉得 Martin Arjovsky 直接用梯度,不过是想写得简单一点,这时候惩罚是:
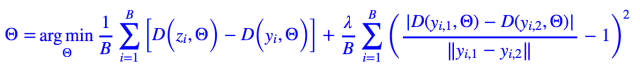
这里 yi,j=εi,jyi+(1−εi,j)zi,也就是每步插值两次,然后用插值的结果算差分。
通过本文,我们可以一气呵成地直达 WGAN-GP,而不需要很多的历史知识和数学知识。有趣的是,我们的推导过程表明,WGAN-GP 其实跟 Wasserstein 距离没有直接的联系,尽管当初 WGAN 的作者是从 Wasserstein 距离将它们推导出来的。也就是说,WGAN 跟 W 没啥关系,这就尴尬了。另外,有人提问“WGAN 相比原始的 GAN 有什么优势?”,如果根据本文的理论推导,那么原始的 GAN 根本就不是 GAN,因为它不能改写为本文的某个特例。(原因在于,本文的推导基于分布的拟合,而原始 GAN 的推导基于博弈论,出发点不同。)
这个 Loss 还有一定的改进空间,比如 Loss Sensitive GAN(LS-GAN),还有更广义的 CLS-GAN(将 LS-GAN 和 WGAN 统一起来了),这些推广我们就不讨论了。不过这些推广都建立在 Lipschitz 约束之上,只不过微调了 Loss,也许未来会有人发现比 Lipschitz 约束更好的对 D 的约束。

PaperWeekly是一个推荐、解读、讨论、报工智能前沿论文的学术平台。如果你研究或从事AI领域,欢迎在PaperWeekly号后台点击「交流群」,小助手将把你带入PaperWeekly的交流群里。返回搜狐,查看更多
推荐: